When you write your home address on a letter, the post office uses it to deliver the mail to the right place. A URL works the same way on the internet. It is the complete address of a page or a site, which tells browsers where the page is.
But calling it just an “address” is oversimplifying. A URL does much more than that. It carries information about how to access a resource, what protocol to use, and sometimes even specific instructions for the browser or server.
In this guide, we’ll explain what a URL is, break down its parts, and explore why it matters for your site’s performance, usability, and SEO.
What Does “URL” Stand For?
The term URL stands for Uniform Resource Locator. It is the “official name” for the web address. It tells the browser where to go and how to fetch a resource.
A URL is a subset of something bigger called a URI (Uniform Resource Identifier). A URI is any string of characters that identifies a resource. There are two main kinds:
- URN (Uniform Resource Name): Names a resource without saying how to find it. Example: urn:isbn:0451450523 identifies a book by its ISBN number.
- URL (Uniform Resource Locator): Both identifies a resource and tells you how to locate it. Example: https://example.com/page.html.
So all URLs are URIs, but not all URIs are URLs. In practice, most people just use the term “URL,” since that’s what we deal with in everyday browsing.
URL vs URI vs URN
These three terms are closely related but not identical. A URL is a type of URI, while a URN is another form of URI that names a resource without giving its location.
| Term | Full Form | Purpose | Example |
| URI | Uniform Resource Identifier | General term for anything that identifies a resource | https://example.com/page.html or urn:isbn:0451450523 |
| URL | Uniform Resource Locator | Identifies and locates a resource on the web (address + protocol) | https://example.com/page.html |
| URN | Uniform Resource Name | Identifies a resource by name but doesn’t give its location | urn:isbn:0451450523 |
Why Do I Need URLs?
Without URLs, the web would be impossible to navigate. They serve several key purposes:
- Uniquely locate web resources: Every page, image, or file on the internet needs a unique address so browsers know exactly where to find it.
- Help browsers find and fetch content: A URL tells the browser which server to contact, what protocol to use, and what file or page to request.
- Allow sharing of addresses (links): Copying and pasting a URL makes it easy to share a specific web page with anyone, anywhere in the world.
Well-structured URLs are not only important for navigation but also for search engine optimization and user experience. This is where our website maintenance service becomes essential.
During updates, redesigns, or migrations, broken URLs can lead to 404 errors, poor rankings, and lost visitors. Pure Website Design ensures that URLs remain clean, functional, and SEO-friendly, keeping your site reliable and discoverable.
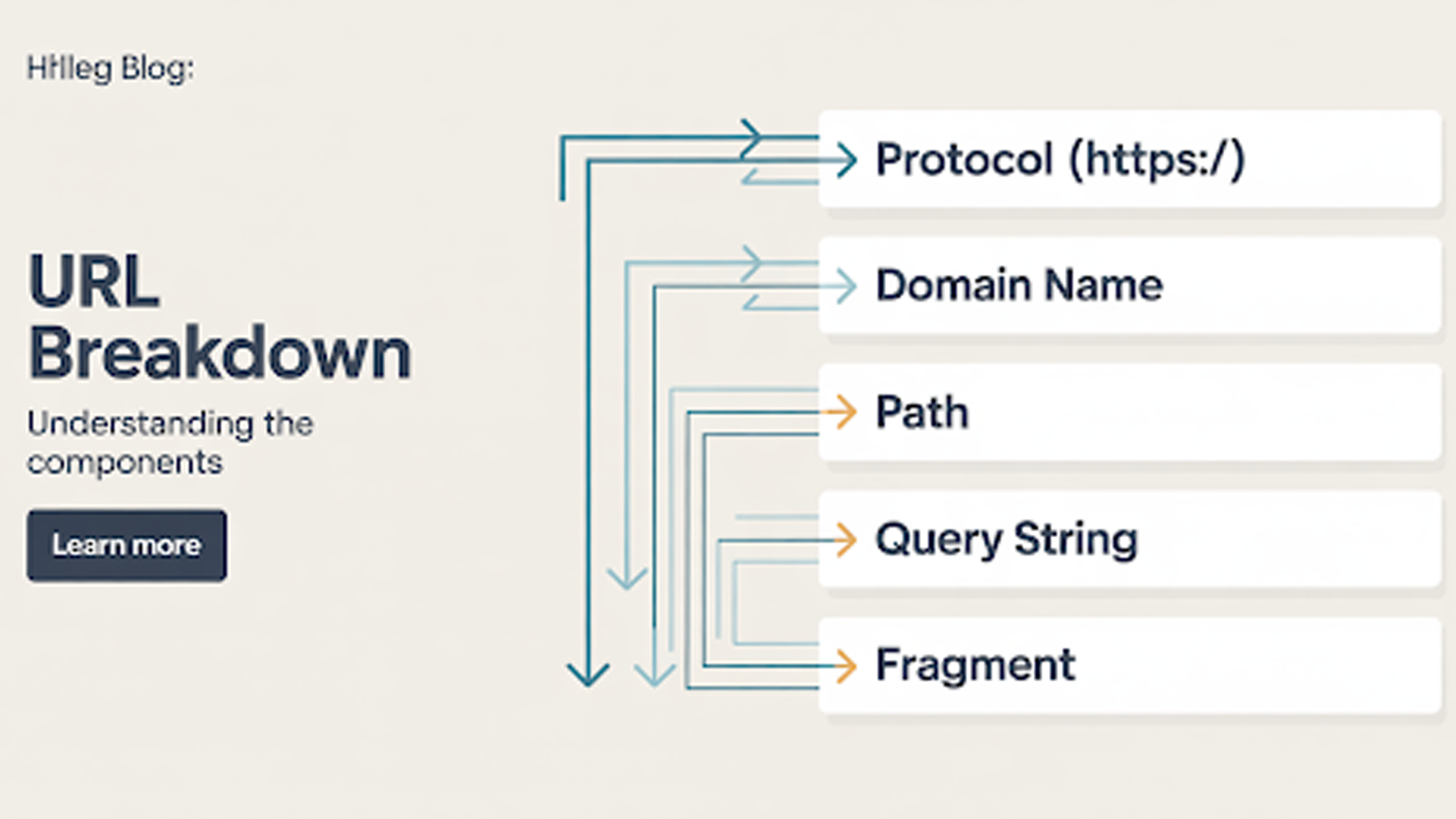
2. Anatomy / Components of a URL
A home address is not written as one piece of information. It is divided into a house number, street, city, and country. Each part has a role and ensures the delivery reaches the right place.
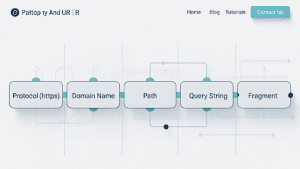
A URL works in the same way. It may look like one string of text, but it is divided into categories. Each section tells the browser something specific: the protocol, the domain, the path, the parameters, and the anchor.
Here is what each part does:
Scheme / Protocol
The scheme, also called the protocol, is the first part of a URL. It defines how the browser and the server communicate.
- Common schemes: Examples include http://, https://, ftp://, and mailto:. Each one tells the browser which method to use for retrieving or sending data.
- Role: The scheme sets the rules for the transfer. For instance, HTTPS adds encryption for secure communication, while FTP is used for file transfers.
- Default ports: Every scheme has a default port number. For example, HTTP uses port 80 and HTTPS uses port 443. If a URL uses the default port, it is usually omitted. Only non-standard ports are shown in the URL, such as http://example.com:8080.
Authority
The authority section comes right after the scheme in a URL. It identifies the server that holds the resource.
- Domain name: The main identifier of the site, such as example.com. It maps to the server’s IP address through DNS.
- Subdomain (optional): A prefix that divides a site into sections, such as www.example.com or blog.example.com.
- Port number (optional): A server entry point. Standard ports are hidden (80 for HTTP, 443 for HTTPS). A non-standard port is shown in the URL, like http://example.com:8080.
- Username and password (rarely used): Older systems sometimes included credentials in the URL, such as ftp://user:password@host.com. This practice is unsafe and is now discouraged.
Path / Resource Path
The path section of a URL comes after the domain. It directs the browser to a specific file, page, or resource on the server.
- Basic path: Written as a series of folders or files, such as /folder/file.html. It shows the route to the resource on the server.
- Abstracted paths: Modern frameworks and content management systems often use routing rules. The path may not reflect an actual file location but instead map to dynamic content, such as /products/shoes showing a product page generated by the system.
- Clean or “pretty” paths: Websites often use simplified, user-friendly URLs that are easier to read and remember. For example, /about-us instead of /index.php?page=about. These paths improve usability and support SEO best practices.
Query String / Parameters
The query string is the part of a URL that starts with a question mark (?). It passes extra information to the server in the form of key–value pairs.
- Basic format: Written as ?key=value&other=value. Each key represents a variable, and each value provides data. Multiple parameters are joined with an ampersand (&)
- Purpose: Used to send data to the server, such as filters, search terms, tracking codes, or session IDs. For example, ?q=shoes&color=black might return all black shoes in a search result.
- Encoding and limits: Special characters are encoded (e.g., spaces become %20). While there is no strict limit, very long query strings can cause issues with browsers or servers.
Fragment / Anchor
The fragment, also called an anchor, is the part of a URL that begins with a hash symbol (#). It points to a specific section within a page.
- Basic format – Written as #fragment, such as example.com/page.html#reviews. This would load the page and scroll directly to the “reviews” section.
- Client-side only – The fragment is processed by the browser, not the server. It is usually not sent in the HTTP request. The server delivers the page as a whole, and the browser uses the fragment to navigate within it.
Types / Variants of URLs
URLs can take different forms depending on how they are written and what they are used for. Some point to complete web addresses, while others are shorter, relative, or designed for specific purposes.
Absolute vs Relative URLs
URLs can be written in two ways. An absolute URL gives the complete address, while a relative URL shows only the path within the same site.
| Type | Description | Example |
| Absolute URL | Full address that includes scheme, domain, and path | https://example.com/products/shoes |
| Relative URL | Only the path, used when linking within the same site | /products/shoes |
Special / Less Common URL Schemes
Not all URLs point to standard web pages. Some use special schemes to handle emails, file transfers, or local resources.
| Scheme | Purpose | Example |
| mailto: | Opens the default email client to send a message | mailto:info@example.com |
| ftp:// | Transfers files between client and server | ftp://ftp.example.com/file.txt |
| file:// | Accesses files stored locally on a device | file:///C:/Users/Docs/file.pdf |
| data: | Embeds small data items directly in a URL | data:text/plain;base64,SGVsbG8sIFdvcmxkIQ== |
How URLs Are Resolved / How They Work Behind the Scenes
A URL goes through several steps from browser to server to fetch and display the right resource.
DNS Lookup & Domain Resolution
When you enter a URL, the domain name is converted into an IP address through the Domain Name System (DNS).
- Domain to IP: DNS acts like a phonebook. It translates a domain such as example.com into the numeric IP address of the server that hosts the site.
- Why this matters: IP addresses are hard to remember, while domain names are simple and human-friendly. DNS makes browsing practical by hiding the complexity behind easy-to-read names.
If a site fails to load correctly, sometimes cached records cause issues. In such cases, it helps to flush DNS so the browser fetches fresh records from the DNS server.
Server Processing
Once the request reaches the server, the web server or application interprets the URL to decide what resource to deliver.
- Reading path and parameters: The server checks the path (e.g., /products/shoes) and any query parameters (e.g., ?color=black) to identify the correct content.
- Routing and rewriting: Many modern sites use URL rewriting. A clean or “pretty” path such as /about-us may internally map to something like index.php?page=about. The user sees a simple URL, while the server handles the complex routing in the background.
Redirects
Redirects are used when a page’s URL changes but you still want visitors and search engines to reach the correct destination. They prevent users from seeing errors and ensure that links pointing to the old URL continue to work.
A permanent redirect (301) signals that the content has moved for good, while a temporary redirect (302) shows that the change is only short-term. Setting up redirects properly is important for SEO because it helps preserve rankings, link equity, and the overall user experience.
Best Practices & SEO Considerations
Clear, consistent URLs improve both user experience and search rankings. Following SEO-friendly patterns ensures your pages are discoverable, secure, and future-proof.
Readability and Simplicity
A clean, descriptive URL is easier for users to understand and for search engines to index. Use short words, avoid unnecessary stopwords, and separate terms with hyphens instead of underscores.
Always keep URLs in lowercase to prevent duplicate variations and ensure consistency across the site.
Avoiding Excessive Query Strings
Long query strings can make URLs look messy and reduce click-through rates. They can also create indexing challenges for search engines.
Wherever possible, structure important data into the path rather than relying on multiple parameters. This improves both usability and SEO performance.
Canonical URLs and Duplicate Content
Search engines often encounter multiple versions of the same content. To prevent dilution of ranking signals, use the <link rel=”canonical”> tag to point to the preferred version of a page.
Combine this with proper redirects to consolidate link equity and strengthen the authority of your chosen URLs.
HTTPS and Secure URLs
Switching from HTTP to HTTPS is no longer optional. HTTPS ensures data integrity, protects user privacy, and has a direct impact on search rankings.
A secure URL also builds trust with visitors, reducing bounce rates and encouraging conversions.
Handling Old URLs and Changes
As sites evolve, URLs often need restructuring. When making changes, always implement proper 301 redirects to preserve SEO value.
Update internal links to avoid broken paths and design a helpful 404 page to guide users back to working content. This protects both user experience and search visibility.
Businesses that rely on uptime often invest in premium DNS for advanced security features, faster propagation, and more control.
FAQs
Can a URL change over time?
Yes, URLs can change due to redesigns, CMS migrations, or SEO updates. If not managed correctly, these changes can lead to broken links and traffic loss. Setting up 301 redirects helps preserve rankings and guide users to the right page.
Are URLs case-sensitive?
In most cases, everything after the domain name is case-sensitive, depending on the server setup. For example, /Blog and /blog might load different pages. It’s best to always use lowercase to avoid confusion and duplicate indexing.
What is the maximum length of a URL?
Browsers typically support URLs up to around 2,000 characters, though it’s best to keep them much shorter. Search engines may truncate overly long URLs, making them harder to read and share. Short, descriptive URLs are more user-friendly and SEO-friendly.
How does URL encoding work with special characters?
When URLs contain spaces or special characters, they are encoded using percent-encoding. For example, a space becomes %20. This ensures browsers and servers interpret the URL correctly without breaking the request.
Why do clean URLs matter for SEO?
Clean, structured URLs help search engines and users understand a page at a glance. A short descriptive path looks more trustworthy and improves click-through rates. Businesses often work with experts like Pure Website Design to create SEO-friendly URL structures.
Can two different websites use the same URL path?
Yes, but the domain makes them unique. For example, example.com/blog and mysite.com/blog are different URLs because the domains differ. The combination of scheme, domain, and path ensures each resource has a unique address.
What happens if an old URL no longer exists?
If an old URL is deleted without a redirect, users see a 404 error page. This can frustrate visitors and harm SEO. The best practice is to redirect old URLs to the most relevant working page or build a helpful custom 404.
How can URL structure affect a website redesign?
A poor URL migration can cause ranking drops, broken links, and lost traffic. Planning redirects and restructuring URLs carefully is essential. Many businesses hire Pure Website Design to handle this process smoothly and avoid long-term SEO damage.
Conclusion
A URL is more than just an address on the internet. It tells browsers where to find resources, helps users share content, and plays a direct role in search rankings. Knowing how URLs are structured and how they work behind the scenes makes web development more efficient and websites easier to use.
Small details like using clean paths, secure HTTPS, and proper redirects can greatly impact both user trust and SEO performance. Taking the time to inspect and improve URLs ensures a site remains accessible, reliable, and future-ready.